GoogleCloud最近宣布了一项开源项目,旨在简化机器学习管道的操作()。在本文中,我将介绍使用现有的TensorFlow模型并使用Kubeflow管道(本文中的KFP:)对该模型进行训练、评估、部署和再训练的过程。

本文的完整代码你可以在GitHub上找到:()
1.创建一个安装了管道的Kubernetes集群KFP自然需要Kubernetes集群来运行。使用此命令启动GoogleKubernetes引擎(GKE)集群并允许KFP管理集群(repo中的create_:):

创建一个GKE集群大约需要3分钟,因此请导航到GCP控制台的GKE部分(),并确保集群已启动并准备就绪。
集群启动后,在GKE集群上安装ML管道(repo中的2_deploy_kubeflow_:):

在发布页面上将上面的版本更改为最新版本()。部署此程序包需要几分钟时间。你可以查看作业的状态并将等待成功运行的次数更改为1。或者你可以告诉kubectl等待创建完成:

在等待软件安装完成时,你可以继续阅读!

有两种方法可以创建管道。"dev-ops"方式是使用Python3和Docker。更加对数据科学家友好的方式是使用Jupyter笔记本。在后面的文章中,我将向你展示Jupyter笔记本方法,但在本文中,我将向你展示Python3-Docker机制。理解这一点有助于你了解当你使用Jupyter方法时幕后发生的事情。
我将用机器学习模型来预测婴儿的体重。该模型具有以下步骤:(a)从BigQuery中提取数据,对其进行转换并将转换后的数据写入云存储。(b)训练TensorFlowEstimatorAPI模型并对模型进行超参数调整。(c)确定最佳学习率、批次大小等参数后,使用这些参数对模型进行更长的、更多的训练。(d)部署训练过的模型到云ML引擎。
以下是描述上述管道的Python代码(repo中的mlp_:):




上面的每个步骤都是Docker容器。Docker容器的输出是另一个(稍后的步骤)的输入,它是一个有向非循环图,当加载到管道UI时,它将如下所示:
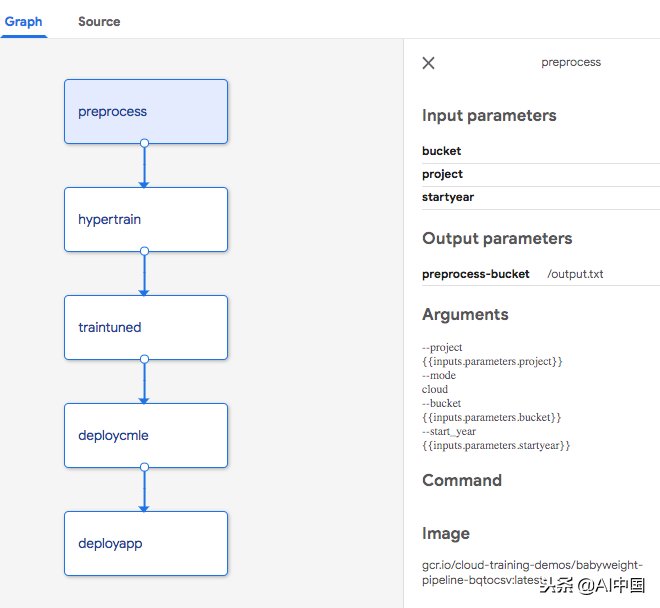
ML管道
(完整的端到端应用程序还包括第五个步骤,部署一个为模型提供用户界面的Web应用程序。)
看一下预处理步骤:

请注意,它使用了两个输入参数——项目和存储桶——并将其输出(包含预处理数据的存储桶)放在/中。
因此,第二步使用预处理获得此存储桶名称,输出['bucket'],并将其输出(最高性能超参数调整试验的作业名)放入管道的第三步,然后将其用作hparam_['jobname']。
非常简单!
当然,这引出了两个问题:第一步是如何获得它需要的项目和存储桶的?其次,如何实施各个步骤?
项目和桶是通过管道参数获得的:

基本上,项目和存储桶将在管道运行时由最终用户提供。UI将使用我在上面提供的默认值预先填充:
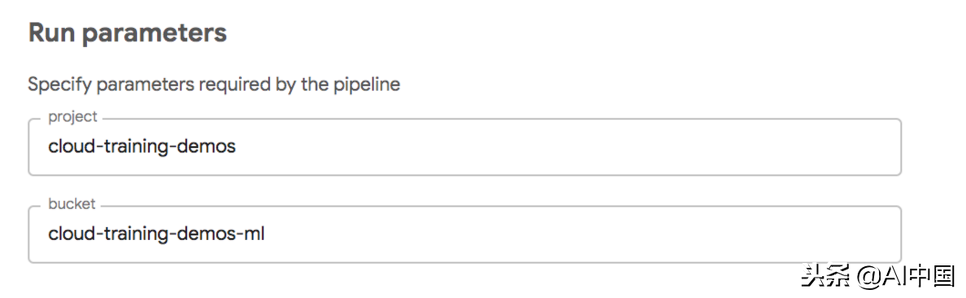
管道参数由最终用户提供
本节的其余部分是关于如何实施各个步骤的。再次,正如我所提到的,我将解释Python3-Docker的实现方式。在后面的文章中,我将解释Jupyter方法。因此,如果你确信自己永远不会使用Docker路线,只需浏览本节或跳到第3节。
2A.预处理
在每个步骤中,你都需要创建一个Docker容器。这本质上是一个独立的程序(bash,Python,C++等等),它的所有依赖项都很好地被指定,以便它可以由集群上的KFP运行。
就我而言,我的预处理代码是一个独立的Python程序,它使用ApacheBeam并期望在CloudDataflow上运行。所有代码都在一个名为的命令行程序中():
预处理代码都在一个名为的文件中
我的Dockerfile必须指定所有依赖项。幸运的是,KFP有许多样本容器,其中一个容器具有我需要的所有依赖项。所以,我只是继承了它。因此,我的Dockerfile()全部为4行:

本质上,我将复制到Docker容器中,并表示入口点是执行该文件。
然后我可以构建我的Docker容器并在()的项目中将其发布到中:

当然,这是我为预处理步骤指定的image_name。
2上的训练和超参数调整
我将使用bash对CloudMLEngine进行训练和超参数调整,以使用gcloud提交作业():

请注意,我使用了gcloud命令等待完成的日志,并注意我在管道代码中写出了作为合同一部分的jobname。
这一次,我将通过继承已经安装了gcloud的容器来创建我的Dockerfile(),然后git克隆包含实际训练师代码的存储库:

2C.在Kubernetes进行本地训练
上面的预处理和超参数调整步骤利用了托管服务。KFP所做的就是提交作业,并允许托管服务执行它们的任务。如何在KFP运行的Kubernetes集群上做一些事情?
让我在GKE集群上进行本地的下一步(训练)。为此,我可以简单地运行一个直接调用python的Docker容器:

在集群本身上执行作业有一个问题。你怎么知道集群还没有执行一些耗尽所有可用内存的任务?traintuned容器操作"保留"了必要的内存和CPU数量。只有在必要的资源可用时,kubeflow才会安排任务:

2D.部署到CloudML引擎
部署到CloudML引擎()也使用gcloud,因此该目录中的和看起来应该非常熟悉:

和

正如我们在Kubernetes集群上进行训练一样,我们也可以在Kubernetes上进行部署(请参阅此组件以获取示例)。
2E.编译DSL
现在所有步骤的Docker容器都已构建,我们可以将管道提交给KFP,但KFP要求我们将管道Python3文件编译成特定于域的语言。我们使用Python3SDK附带的名为dsl-compile的工具来实现这一点。所以,首先安装该SDK(3_install_:):

然后,编译DSL:

这个tar文件将在第3节中上传到ML管道UI。
3.上传用户界面服务器在端口80中的GKE集群上运行。执行端口转发,以便你可以从笔记本电脑访问端口8085(4_start_:):

现在,打开浏览器到http://localhost:8085/pipeline并切换到Pipelines选项卡。然后,将第2E节中创建的文件作为管道上传。
这只是简单地使图表可用。你可能会使用各种设置组合来运行它。因此,开始实验以保持所有这些运行。我将我的实验命名为"博客",然后创建了一个运行。我命名运行'try1'并使用刚刚上传的管道进行设置:
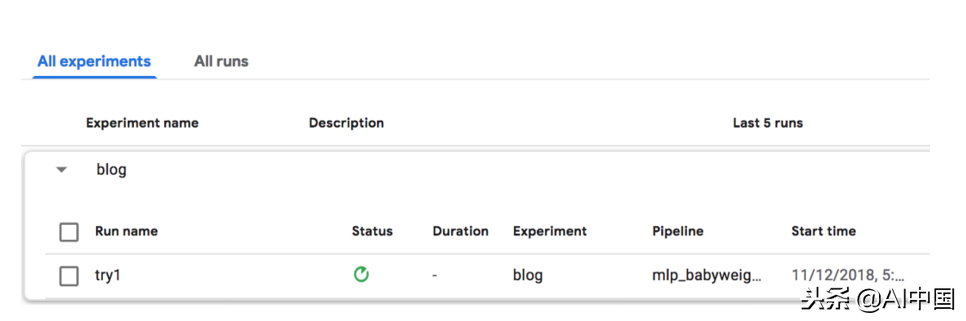
管道现在开始运行。我可以看到正在执行的每个步骤以及每个步骤的日志:
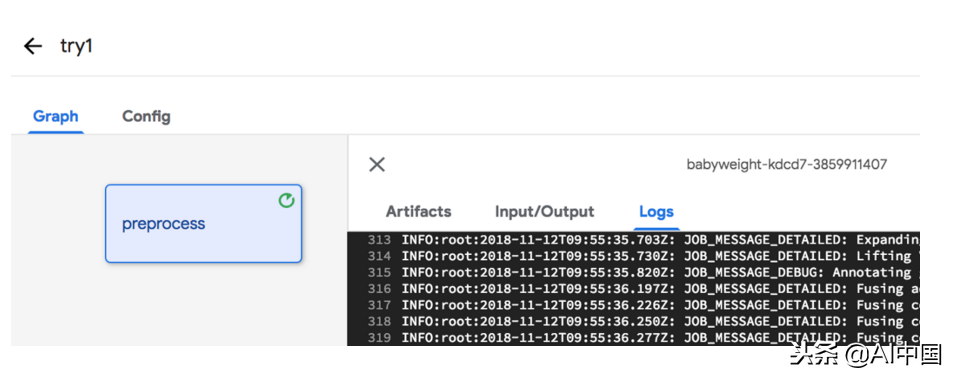
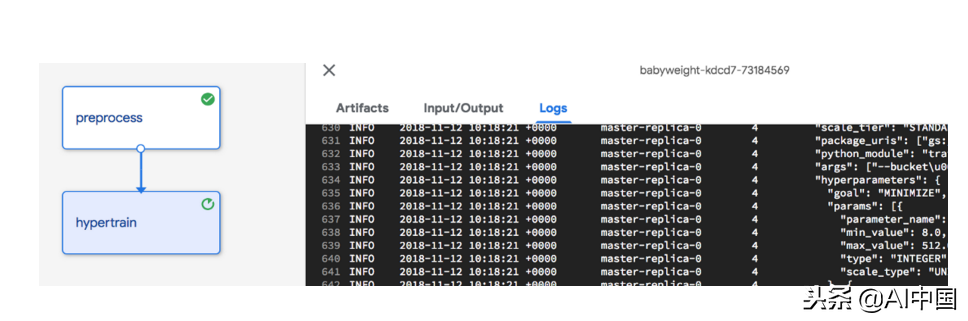
完整的源代码包含了我忽略的一些内容。显然,完整的代码似乎没有完全形成,并且第一次没有正常工作。我不是每次都从头开始启动管道,而是设置管道,以便我可以从任何步骤(我正在处理的步骤)开始。
但是,每个步骤都取决于上一步的输出。这该怎么做?这是我的解决方案:

基本上,如果start_step≤2,则创建容器op。否则,我只需创建一个具有上一步"已知"输出的字典。这样,我可以简单地将start_step设置为4以从第4步开始,跳过前面的步骤。但是,后面的步骤将具有他们期望的任何先前步骤的输入。
我的实验包括几个部分:
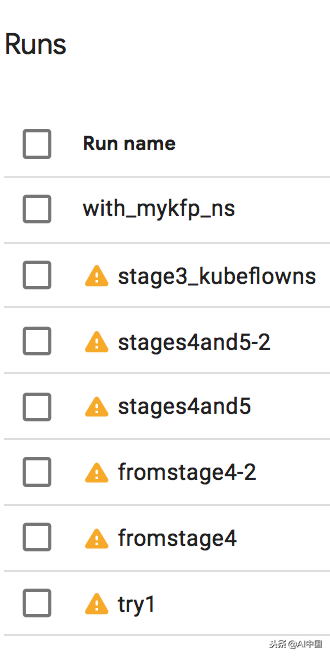
例如,try1在成功运行3个步骤后失败,我可以从第4步开始。我需要两次尝试才能使第4步正确。然后,我添加了第5步(它部署了一个AppEngine应用程序来支持Web服务)。然后,我回去尝试了第3阶段的不同变化。
4B.再训练
当然,你不会只训练模型一次,然后让它永远消失。一旦有更多数据,你将需要重新训练模型。在我们的婴儿体重模型中,我们可能会想象,一旦我们有一年的数据,我们会重新再训练模型。我在管道中处理这个问题的方法是要求startYear作为输入参数:

bqtocsv步骤中的预处理代码仅在开始年份/之后提取行:

并命名输出文件,以便它们不会破坏早期输出:

训练现在发生在更大的数据集上,因为模式匹配是针对train*的。
当然,还有其他方法可以处理再训练。我们可能会采用以前的模型并仅根据较新的数据进行训练。像这样的语义并不难加入——使用命名约定来帮助管道做正确的事情。
4C.评价?笔记本电脑?
当然,通常情况下,你不会立即将经过训练的模型推向生产。相反,在切换所有流量之前,你将进行一些评估并进行A/B测试。
此外,你不会在Docker容器中进行开发。我很幸运,因为我的babyweight模型几乎是一个Python包,对Dockerize来说相当方便。如果你在Jupyter笔记本中进行所有模型开发怎么办?
如何进行评估,以及如何将笔记本转换为管道是另一篇博文的主题。
作者——LakLakshmanan






