
这里所做的所有工作都是在googlecolabs上完成的,使用的notebook可以在Github上找到:
步骤1-获取数据不幸的是,我找不到一个适合我在Kaggle上或使用Google的数据集搜索的预先制作的图像数据集。所以,我准备建立我自己的!
我决定使用ASPCA的《猫和狗的植物毒性清单》,我已经用了好几次了。这给了我们一个很好的核心工作。为了从网站上获取这些文本数据,我们可以求助于BeautifulSoup,这是一个Python库,用于从HTML和XML文件中提取数据。
,urlopenfrombs4importBeautifulSoupdefgetHTMLContent(link):html=urlopen(link)soup=BeautifulSoup(html,'')returnsoup
然而,当查看他们的网站时,该表并不是一个易于访问的html表,而是将数据存储为面板中的行。幸运的是,beauthulsoup为我们提供了一种简单的方法来搜索解析树,以找到我们想要的数据。例如:
req=Request('',headers={'User-Agent':'Mozilla/5.0'})webpage=urlopen(req).read()搜索解析树以从表中获得所有内容content_list=_all('span')[7:-4]清理字符串df_cats[0]=df_cats[0].apply(lambdax:str(x).split('')[1][:-3])df_cats[4]=df_cats[4].apply(lambdax:str(x).split('')[1][:-3])df_cats[1]=df_cats[1].apply(lambdax:str(x).split('(')[1][0:-4])将有毒和无毒植物分开df_cats['ToxictoCats']=Truefirst_nontoxic_cats=[indexforindexindf_cats[df_cats['Name'].('A')].indexifindex100][0]df_[first_nontoxic_cats:,'ToxictoCats']=False然后,我们可以对特定于狗的列表重复此过程,然后合并数据帧并清理nan:
假设对猫和狗有相同的毒性aspca_df['ToxictoCats']=aspca_(lambdax:x['ToxictoDogs']if(x['ToxictoCats']=='Unknown')elsex['ToxictoCats'],axis=1)aspca_df['ToxictoDogs']=aspca_(lambdax:x['ToxictoCats']if(x['ToxictoDogs']=='Unknown')elsex['ToxictoDogs'],axis=1)

接下来,我们可以开始进行浅度清理,包括查看数据集,决定要使用哪些关键特征,并标准化它们的格式。
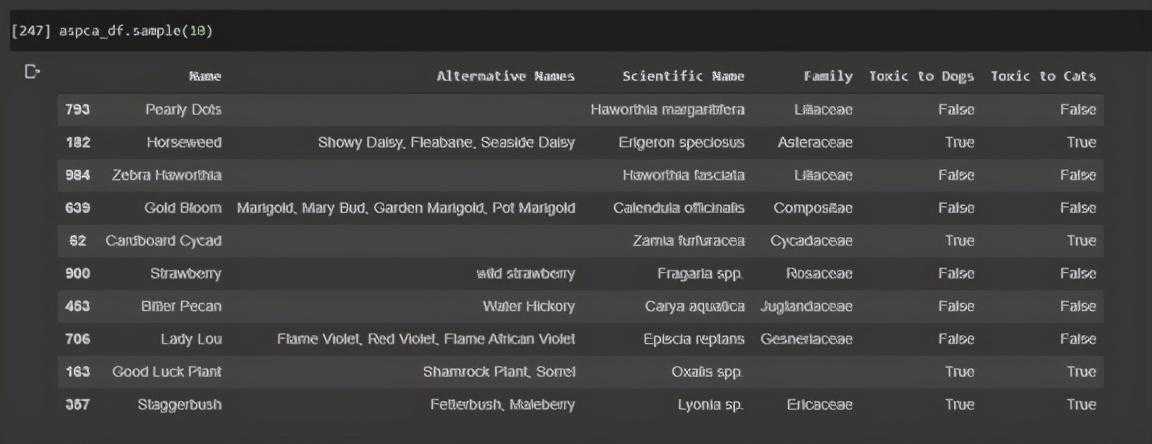
我们目前有名字,替代名称,学名,家族以及毒性列,所有这些都是从用BeautifulSoup在ASPCA网站上爬来的。
由于我们将使用谷歌图像搜索收集图像,因此我们决定根据每种植物的确切学名进行搜索,以获得尽可能具体的图像。像“珍珠点”、“大象耳朵”、“蓬松褶边”和“粉红珍珠”这样的名字会很快返回我们所寻找的植物之外的结果。
我们编写了几个快速函数来应用于该系列,以尝试将数据标准化以便进一步清理。
清理那些名字不同的重复物种defspecies_normalizer(word):()[-1]in['sp','species','spp','sp.','spp.']:word=''.join(()[:-1])returnword从名称中删除vardefvar_remover(word):if'var'inword:word=('var.','')returnword删除特殊字符aspca_df['ScientificName']=aspca_df['ScientificName'].apply(lambdax:''.join([()()]))读取WFO数据,只保留有用的列use_cols=['scientificName','taxonRank','family','genus','taxonomicStatus','taxonID','acceptedNameUsageID']wfo_df=_csv('/content/drive/MyDrive/HouseplantClassifier/',sep='\t',lineterminator='\n',usecols=use_cols)wfo_df=wfo__values('taxonomicStatus')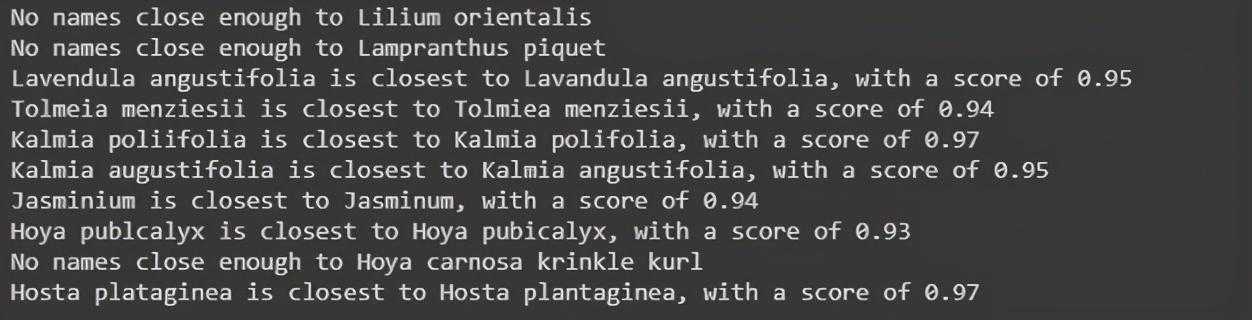
作为第一步,我们将对来自ASPCA的数据进行左合并,保留我们的所有类,并添加与我们当前拥有的确切学名匹配的任何数据。我们的目标是将数据库中的所有植物更新为最新的可接受的学名。
合并数据文件以获得可信信息aspca_df=aspca_(wfo_df,how='left',left_on=['ScientificName'],right_on=['scientificName'])用Unknown来填满NaNaspca_df=aspca_('Unknown')步骤3.1-用字符串匹配修复印刷错误许多学名指的是同一物种,但由于在ASPCA数据库中的打字错误,有几个字母被删掉了。让我们使用difflib中的SequenceMatcher来量化字符串距离,通过比较WFO数据库中不匹配的条目来发现这些错误。
我们可以对数据帧进行排序,只与以同一字母开头的学名进行比较,以节省时间。如果名称足够相似,我们将保留它并最终返回最接近的匹配项。这里我们将阈值设置为0.9,以避免任何不正确的匹配。
defget_closest_name(unknown_name,name_df=wfo_df,name_col='scientificName',threshold=0.9,verbose=False):"""将'unknown_name'与'name_df'中接受的名称进行匹配。将返回超过接近的“threshold”的名字.Parameters----------unknown_name:str我们希望与该名称进行匹配.name_df:DataFrame包含名称的数据框.name_col:str,nameofname_dfcolumn包含可接受名称的列threshold:intunknown_name需要在多大程度上与接受的名称匹配如果超过这个阈值,名称将被添加到可能的名称字典中verbose:bool函数是否打印整个列表Returns:----------str与‘unknown_name’最接近的、高于给定‘阈值’的名称。"""importoperatorfromdifflibimportSequenceMatcherdefsimilar(a,b):returnSequenceMatcher(None,a,b).ratio()poss_names={}如果dict为空ifverbose==True:print(poss_names)ifnotbool(poss_names):print(f'Nonamescloseenoughto{unknown_name}.')return''else:print(f'{unknown_name}isclosestto{max(poss_(),key=(1))[0]},withascoreof{max(poss_(),key=(1))[1]:.2f}')returnmax(poss_(),key=(1))[0]我们还定义了一个函数来修复数据中的问题条目,它将把它们的学名、科、属和分类状态更新为WFO数据库中的(正确的)相应条目。
deffix_name(unknown_name,true_name):"""根据已接受的wfo_df条目修复aspca_df条目.Parameters----------unknown_name:str我们想要修复的名字.true_name:DataFrame修复的名称."""根据ID查找从wfo数据库中获取已接受的数据true_data=wfo_df[wfo_df['scientificName']==true_name]true_sciname=true_[:,'scientificName'].values[0]true_family=true_[:,'family'].values[0]true_genus=true_[:,'genus'].values[0]true_taxonomicStatus=true_[:,'taxonomicStatus'].values[0]更新剩下的已接受的学名的同义词学名aspca_df=aspca__values('taxonomicStatus').drop_duplicates('ScientificName',keep='first').reset_index(drop=True)synonym_idx=aspca_df[aspca_df['taxonomicStatus'].values=='Synonym'].indexforiinsynonym_idx:根据ID查找从wfo数据库中获取已接受的数据true_data=wfo_df[wfo_df['taxonID']==synonym_['acceptedNameUsageID']]true_sciname=true_[:,1].values[0]fix_name(synonym_name,true_sciname)幸运的是,WFO数据库包含一个acceptedNameUsageID字段,该字段包含给定同义学名的可接受名称,我们可以利用该字段查找接受的学名并将其传递到fix_name函数中。
步骤3.4-结束现在,我们已经纠正了拼写错误(自动和手动),并将发回的同义词与最新的已接受名称进行了匹配。剩下的就是清理图像下载的数据帧。
设置一个单词名称的属作为名称,而不是NaNaspca_[aspca_('Unknown')['genus']=='Unknown','genus']=aspca_[aspca_('Unknown')['genus']=='Unknown','ScientificName']标准化列名aspca_(columns={'genus':'Genus','family':'Family'},inplace=True)如果运行在Colab!pipinstallselenium-q!apt-getupdate导入并设置Seleniumwebdriverfromseleniumimportwebdriverchrome_options=()chrome__argument('--headless')chrome__argument('--no-sandbox')chrome__argument('--disable-dev-shm-usage')wd=('chromedriver',chrome_options=chrome_options)importrequestsimporttimedeffetch_thumbnail_urls(query:str,max_links_to_fetch:int,wd:webdriver,sleep_between_interactions:int=1,non_commercial=False,shuffle=False):"""使用Seleniumwebdriver(wd)根据查询从谷歌图像中收集url可以将sleep_between_interactions更改为适应较慢的计算机。如果shuffle为真,则返回的url列表将被打乱为随机顺序Parameters----------query:str传递给谷歌图像。max_links_to_fetch:int要获取的url数目。wd:Seleniumwebdriver要使用的webdriver实例。sleep_between_interactions:int在webdriver交互之间等待的时间(秒)。non_commercial:bool标记仅为非商业用途。shuffle:bool返回的url顺序是否打乱。Returns:----------Listurl的列表。"""defscroll_to_(wd):_script("(0,);")(sleep_between_interactions)加载页面(search_(q=query))image_urls=[]image_count=0results_start=0whileimage_countmax_links_to_fetch:scroll_to_(wd)提取图像url,如果它们是可用的地址_attribute('src')and'http'_attribute('src'):image_(_attribute('src'))如果我们达到指定的配额就中断iflen(image_urls)=max_links_to_fetch:break移动指针results_start=len(thumbnail_results)ifshuffle==True:(image_urls)returnimage_urls太好了!现在我们有了一种从谷歌图片中获取图片的方法!为了下载我们的图片,我们将利用。然而,我们将深入研究源代码并对其进行一点升级,以便在图像进入时对其进行哈希处理,并忽略/删除任何重复项,以便最终得到一致的唯一图像集。我们还将允许它解码和下载编码的.jpg和.png图像,这是谷歌图像用来存储缩略图的格式。
设置哈希以防止复制图像下载ifurlsisNone:urls=url_().strip().split("\n")dest=Path(dest)(exist_ok=True)输入是一个枚举对象i,url=inpsuffix=(r'\.\w+?(?=(?:\?|$))',url)suffix=suffix[0]iflen(suffix)0else'.jpg'函数处理base64编码的图像函数处理base64编码的图像如果抓取的url是一个http站点,下载它,并检查我们还没有得到相同的图像。try:download_url(url,dest/f"{i:08d}{suffix}",overwrite=True,show_progress=True,timeout=timeout)im=(dest/f"{i:08d}{suffix}")filehash=(()).hexdigest()iffilehashnotinhash_keys:hash_keys[filehash]=ielse:(dest/f"{i:08d}{suffix}").unlink()exceptExceptionase:f"Couldn'tdownload{url}."现在,我们可以遍历我们的每一个科学植物名称,收集它们的网址,然后下载这些图片,同时验证这些图片是否是唯一的。每一组图像都下载到Colabs上我的链接驱动器中自己的文件夹中。需要注意的一点是,由于googleimages上存在大量重复的图片,要抓取的url数量必须远远大于你最终想要的图片数量。
循环所有室内植物的名字,抓取url并下载到我的谷歌驱动器fornameintqdm(scientific_names):try:path=Path('/content/drive/MyDrive/HouseplantClassifier/plant_images_deepest');folder=namedest=path/(parents=True,exist_ok=True)iflen(())150:print(f'{name}has{len(())}images.')url_science=fetch_thumbnail_urls(f'{name}',max_links_to_fetch=600,wd=wd,non_commercial=False,shuffle=False)dest=path/folder#强制刷新hash_key—在函数中作为全局变量存储,这里清空hash_keys=dict()download_images(path/folder,urls=url_science,max_pics=150)print(f'Finisheddownloadingimagesof{name}:{len(())}imagesdownloaded.')else:print(f'{name}alreadyhassufficientimages.')exceptExceptionase:print(f'Errorwith{name}.{e}')下载后,我们将采取步骤确保每个文件夹包含正确数量的唯一图像。
因此,在这个阶段,这些图片被整齐地分到各自的文件夹中,并直接放在我们的谷歌硬盘上。需要注意的是,如果你想用这些图片来训练CNN,如果你在使用它们之前把这些图片带到本地的Colab环境中,但这将在下一篇文章中进一步讨论。
最后从零开始构建数据库图像分类项目对于简单的玩具示例来说很简单,参见一个棕色/黑色/泰迪熊分类器的好例子()。对于这个项目,我想扩展相同的方法,但将其应用到更大的类集合中。这个过程实际上可以分为几个步骤:
获取类列表
由于beauthulsoup,从web页面中获取表格或文本数据非常简单,通常只需要通过正则表达式或内置python方法进行更多处理。
清理和验证下载数据的准确性是这一步中最大的挑战。当我们有10个类和领域知识时,在继续之前很容易发现错误并修复它们。当我们有500个类,事情就变得更难了。一个独立的数据源是至关重要的,我们可以根据它来验证我们的数据。在这种情况下,我们信任ASPCA数据中的毒性信息,但不信任它们提供的学名,因此必须使用WFO数据库对其进行更正,后者提供了最新的分类信息。
获取每个类的图像url列表
我们可以执行搜索,找到缩略图并下载,甚至可以下载得到更大分辨率的图像。
将每个图像下载到带标签的文件夹中
用于下载图像的fastai函数运行良好,但是一个主要的绊脚石是下载重复的图像。如果你想要更多的图片(10-15张),并且你下载了谷歌图片搜索的所有结果,你很快就会得到大量的图片副本。此外,该函数无法处理base64编码的图像。值得庆幸的是,fastai提供了它们的源代码,可以对其进行修改,以解释编码的图像以及下载http链接,下载后对它们进行哈希处理,并且只保留唯一的图像。





